A summary of MapReduce: Simplified data processing on large clusters
Abstract
Working with large data sets on a single computer are prone to quickly get complicated, even with a single computation has multiple stets to com- plete before the calculation of the data can begin. This paper provides a solution to run computations on a large data set with the complicated aspect. MapReduce is a set of functions Map and Reduce, this set of functions provide abstraction to automate memory management and par- allelization across large designed clusters, with built in failure handling.
1. Introduction
The new era of computing large scale data sets were a huge undertaking and unorganized. The collection of raw data had stared to set roots. The collected data were documents, logs, etc. Every time there was a need for some type of computation, the developers were forced to develop for the specific data set, i.e. developers had to consider parallelization, fault tolerance. This special code-bases were costly and and the developers required special technical skills to execute the code in a cluster. Other complications developers could encounter are memory management, I/O bus overflow. Furthermore, the data had to be distributed amongst a cluster of nodes (computers). Otherwise would the computation not be finished in a reasonable time frame.
To solve the problem for running large data set on a cluster, the code complexity had to be chipped down by abstraction. The goal were to hide away the complex code parts and automate the complex processes and to create a framework. The framework they came up with was called MapReduce. MapReduce contains two functions: Map and Reduce. MapReduce was introduced to remove the special designed solutions, and to create a simplified general solution able to be implemented on a cluster with a variety of data sets. This simplification made it easy and more available for less experienced developers to adapt.
2. Implementation
MapReduce is a set of functions that contains: Map & Reduce. The Map function takes an input in the form as an input/value pair. The goal is to associate values that have the same key I. The Reduce produce an output of key/value pairs. The Reduce function accepts the key I and its associated values. Afterwards, Reduce merge the values to possible reduce the data into a smaller data set.
To make any sort of computations on a large data set there are a few structural p arts of the cluster that needs to be considered. The structural parts for MapReduce are the following : one master node, and worker nodes (Map-workers and Reduce-workers). Furthermore, the master node do have some limitations, when the master node performers scheduling, which require a complexity O(M + R) and a complexity of O(M * R) for the memory state. The worker nodes have two properties: an id, and a state. The state contains of three different sub-states during execution (idle, in-progress and complete). An input file is split up into chunks and sent to the Map-workers (MW) and apply a computation defined by the user, see Figure 1. The result from these computations are stored locally on the MW. The MW changes there sate from in-process to complete, the master node gets notified by the completion and give the path where the MW has stored their data to the Reduce-workers (RW). The RW then output R files.
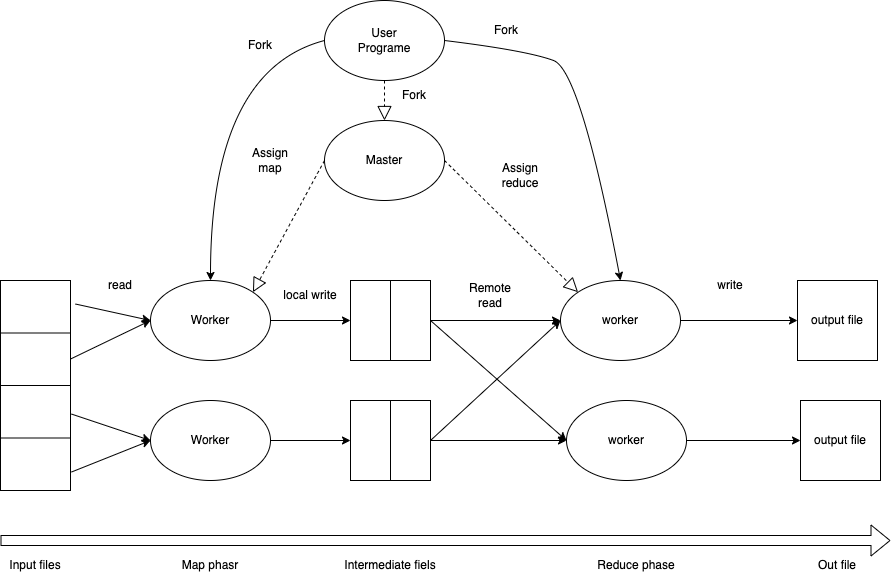
Figure 1. An overview of the structure of MapReduce
is a simplified view of the structural design of how MapReduce work. It starts with an input file at the left. The data file is then traveling through the MW’s, continuing towards the RW’s which finally produces the output files as mentioned earlier. The master node does ping all the nodes to keep the up-time and computations under control.
However, to assure the optimal workflow for the nodes, there is a condition that must be met. Since Map is divided into into M chunks, and the Reduce into R chunks. M and R should preferably be substantial larger than the amount of nodes in the cluster.
The different states mentioned above, are important for the fault tolerance of the cluster. The master node is configured to ping the workers during the computations. However, if a node do not respond in set time frame, the master node does fail the worker node and assign the task to another free node. The failed nodes is then put into an idle state to get new task assigned. When the node have achieved a complete state, the content of the local disk is moved to a global storage system. This structure design of the cluster makes it resilient towards failures amongst the worker nodes.
3. Experiment
Two experiments were conducted in the paper. The first one was a sort and the second is a searches. However, since the paper is from 2008, the technology used are low performing for today’s standard.
The internal network were designed as a tree with two levels. The total theoretical speed the network including the aggregated bandwidth were approximate 100-200 Gb/s. Each of the nodes were configured with an 1Gb/s network port. All the testing were conducted within the same building.
3.1 Sort
The authors created a program based on a benchmark (TeraSort) to conduct the test. The program is designed to sort approximately one terabyte of data. The main goal is to send the data into the MapReduce which give the data indexes the data (key/value, see Solution). Afterwards, the program splits the data chunks and perform the same sort again. The input file was divided into 64MB chunks, a total of M = 15000. The output file was divided into R = 4000 separate files. The Map complete executing under 200 seconds for $10^{10}$ 100-bytes, and the input rate is 13 GB/s (13000 MB/s) compared to a single HDD (Hard Disk Drive) which have a theoretical write speed between 126-160 MB/s depending on sort of workload the drive are designed for. Each node within the cluster had an IDE (Integrated Drive Electronics) disk with a total size of 160GB.
3.2 Search
The search experiment was based on grep, grep is a scanning program, who searches for patterns withing characters. The file size for the grep program is the same size as the sort ($10^{10}$ 100-bytes). The input file was divided into 64MB chunks, a total of M = 15000. The output file was only R = 1 (one single file) file. Grep searched with a speed of 30 GB/s (30000 MB/s) with a cluster size of 1764 workers. The actual search completed in approximately 80 seconds, and the overall time for the search was around 150 seconds. Including startup for the cluster, and overhead. The overhead bases form the opening and searching through all input files, to gather enough information for optimization.
The search has a higher input rate compared to the sort experiment. This is because of the I/O bandwidth when the Map task is writing to its local storage (it takes approximately half of the time).
4. MapReduce’s impact
MapReduce have been applied in many different research projects. One paper who uses machine learning (ML) to detect strokes applied MapReduce to accelerate the processing time. MapReduce achieve this by its efficiency to handle large amount of data.
Researchers have applied MapReduce in data mining to extract hidden information in data in the energy field. By applying MapReduce results in processing on large amount data, which results in finding e.g. associations between data points. However, if there are more nodes than data, an issue for the cluster to load balance the workload. Load balancing is a method to balance the workload as evenly as possible amongst the nodes This means that the cluster runs optimal when all nodes within the cluster are assigned a workload, hence there needs to more data than nodes.
If the master node does fail during execution, the MapReduce abort the execution and the user needs to look into the masters current condition and then re-execute the program.
5. Conclusion
MapReduce have had an successful impact for handling large amount of data, this method has been applied in machine learning to as well e.g. to extract information for the model. Furthermore, the developers made it easy for none-specialist to apply the method through abstraction, in other words restrictions were introduced for the programming model (MapReduce), hence made it easy for adoption. The prevention of redundant executions can help to reduce slow nodes.
There are no details of the specific type of HDD used only that it is an IDE disk, however the speed achieved from combining multiple nodes is an enormous increase in compute speed comparing to computing a single computer.
Moreover, if there are smaller data sets, there is a possibility to use a smaller amount of nodes to achieve optimal conditions for the cluster. However, there will be an decrease of compute power to achieve the load balancing, this balancing is a choice the developer must make.
References
[1] Hdd features & benefits. https://www.westerndigital.com/solutions/internal-hdd. Accessed: 2022-12-07.
[2] Speed test your hdd in less than a minute. https://hdd.userbenchmark.com. Accessed: 2022-12-06.
[3] Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, David E. Culler, Joseph M. Hellerstein, and David A. Patterson. High-performance sorting on networks of workstations. In Proceedings of the 1997 ACM SIGMOD Inter-national Conference on Management of Data, SIGMOD ’97, page 243–254,New York, NY, USA, 1997. Association for Computing Machinery.
[4] Jeffrey Dean and Sanjay Ghemawat. Mapreduce: Simplified data processing on large clusters. (1), 2004.
[5] Jeffrey Dean and Sanjay Ghemawat. Mapreduce: Simplified data processing on large clusters. Commun. ACM, 51(1):107–113, jan 2008.
[6] Carlos Fernandez-Basso, M. Dolores Ruiz, and Maria J. Martin-Bautista. A fuzzy mining approach for energy efficiency in a big data framework. IEEE Transactions on Fuzzy Systems, 28(11):2747–2758, 2020.
[7] Colby Ranger, Ramanan Raghuraman, Arun Penmetsa, Gary Bradski, and Christos Kozyrakis. Evaluating mapreduce for multi-core and multiprocessor systems. In 2007 IEEE 13th International Symposium on High Performance Computer Architecture, pages 13–24, 2007.
[8] Manjula Shanbhog and Kalpna. Load balancing research paper. 07 2020.
[9] Huiling Shao, Xiang Chen, Qilin Ma, Zhiyu Shao, Heng Du, and Lawrence Chan. The feasibility and accuracy of machine learning in improving safety and efficiency of thrombolysis for patients with stroke: Literature review and proposed improvements. Frontiers in Neurology, 13, 10 2022.